目标
需要弄懂下面的问题:
- map的基本数据结构定义
- map的增、删、改、查的实现
- 扩容机制
- range map为什么是无序的
- map为什么不安全,以及sync.Map为什么安全
工具
go tool compile -S main.go
通过上面命令可以输出汇编指令,方便获取实际调用的方法。
数据结构
map对应的数据结构为
hmap:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
const (
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
)
type hmap struct {
count int // 指map的count数量
flags uint8 // 迭代map或者对map进行写操作的时候,会记录该标志位,用于一些并发场景的检测校验
B uint8 // 存放当前map存放的bucket数组长度的对数,即len(buckets) == 2^B
noverflow uint16 // 溢出的bucket数量
hash0 uint32 // hash函数种子
buckets unsafe.Pointer // buckets桶的头指针,增删改查都需要相对头指针偏移计算获取目标数据地址
oldbuckets unsafe.Pointer // 只有扩容的时候不是nil,指向旧的buckets
nevacuate uintptr // 下一个扩容的桶编号
extra *mapextra // optional fields
}
type mapextra struct {
overflow *[]*bmap // 已经使用的溢出桶
oldoverflow *[]*bmap // 旧桶使用的溢出桶
nextOverflow *bmap // 下一个空闲溢出桶
}
// runtime下的源码
type bmap struct {
tophash [bucketCnt]uint8
}
// 编译期间,反射的类型
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
|
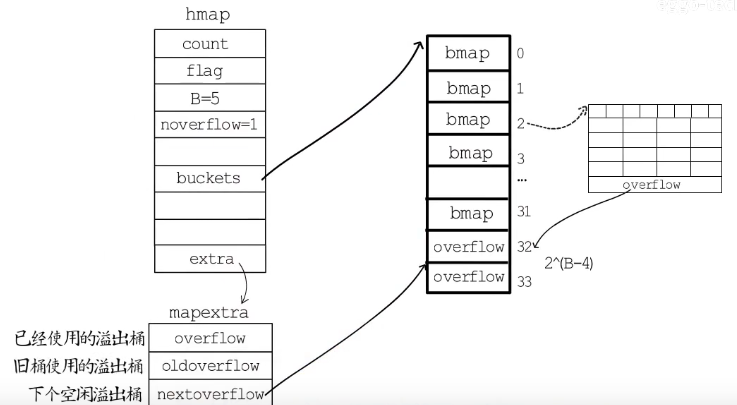
由上面的数据结构可以知道:
B作为2的幂次,意义是方便通过bucket := hash & bucketMask(h.B)定位到key和哪个bucket关联- 如果分配桶的数目大于2^4次方,会分配2^(B-4)次方个溢出桶
增刪改查
创建
1
2
3
4
5
6
7
|
package main
func main() {
m1 := make(map[int]int)
m2 := make(map[int]int, 10)
_, _ = m1, m2
}
|
上面m1初始化调用的
runtime.makemap_small,编译期能确定map长度小于bucketCnt,没有初始化bucket。m2初始化调用
runtime.makemap,通过传入的size,获取对应的对数B进行初始化。
查询
查询某个key的流程如下:
- 将k1通过Hash函数生成64位二进制数d1
- 将d1和hmap的B-1值进行与操作获取具体bucket号
- 遍历前面获取到的bucket,将d1的首8位和bucket里的tophash值进行比较查找,查找到了即拿当前索引去计算值的索引返回值。没有查找到就看啊可能overflow是否为空,不为空则查找关联的下一个bucket
map的查询访问涉及下面两个函数,
mapaccess2多了一个key是否存在的返回值:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointerfunc mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
增加和修改
不考虑扩容的情况下,map的增加与map的查询访问基本逻辑是一致的。首先遵循map访问的方式通过后B位定位bmap,通过前8位快速比较tophash。当map中不存在这个key,会记录bmap中的第一个空闲的tophash,并插入该key。当map中存在这个key,会更新该key的value,涉及到的函数主要是
mapassign
删除
map的删除与map的查询访问基本逻辑也是一致的。遍历bmap与overflow寻找目标key,如果找到则清空tophash并删除key/value释放内存,涉及的函数时
mapdelete
扩容机制
map扩容的目的时解决Hash冲突,防止复杂度增加,尽量保持算法O(1)的时间复杂度。Golang的map扩容时渐进式扩容,写入操作中发生,触发扩容的时机有以下两个:
- 情况一,
overLoadFactor函数计算count/2^B(长度/桶)是否大于6.5,大于就进行2倍扩容,即
hmap.B++
- 情况二,map存在局部bmap包含过多overflow的情况(B <= 15 && noverflow >= 2^B || B > 15 && noverflow >= 2^15),此时map会认为局部的bmap可以进行tophash密集排列,进行等量扩容,创建一样多的新通,将旧桶迁移到新桶,进行密集排列
不知道6.5这个阈值怎么定下来的,每个桶装8个,定个6.5 😅。
range map为什么是无序的
遍历map对应的函数分别是
runtime.mapiterinit和
runtime.mapiternext:
1
2
3
4
5
6
7
8
9
10
|
// decide where to start
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// iterator state
it.bucket = it.startBucket
|
如上面代码所示,在遍历开始的时候,随机取的开始bucket,所以每次遍历的顺序都不一样,但是理论上是开始bucket不一样,但是整体bucket是按照写入顺序的。
map为什么不安全,以及sync.Map为什么安全
官方设计就是不支持多个协程进行map的并发读写操作,相关源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// flags
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same size
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
}
// ... mapassign / mapdelete / mapiternext / mapclear 也一样,这里省略
|
至于sync.Map为什么安全,见
golang-sync-map。
Reference