通过GopherCon TW 2020的分享来理解下逃逸分析。
什么是逃逸分析
C/C++没有垃圾回收机制,都是开发人员进行内存分配,要么分配到栈,要么分配到堆上,同时堆内存对象的生命周期管理给开发人员带来了心智负担,为了降低这方面的心智负担,有的编程语言比如Go、Java就支持了垃圾回收,当分配到堆上的对象不再被引用时,就会被回收。
垃圾回收带来了便利,但是也带来了性能损耗,堆内存对象过多会给垃圾回收带来压力,所以需要尽量减少在堆上的内存分配。
逃逸分析(escape analysis)就是在程序编译阶段根据程序代码中的数据流,对代码中哪些变量需要在栈上分配,哪些变量需要在堆上分配进行静态分析的方法。
栈 vs 堆
Go中声明变量的具体分配策略如下:
- 堆上
- 全局存储空间
- 共享的存储对象
- 被GC管理的存储对象
- 栈上
- 函数内部的本地存储空间
- 协程自己的栈帧
- 私有的存储对象
- 帧生命周期内的存储对象
从变量声明角度,堆和栈的差异:
- 在栈上分配的对象比在堆上快很多
- 协程可以完全控制自己的栈帧
- 栈上,没有锁,没有GC,开销少
下面通过Benchmark来证明栈的优势,具体代码参考 escape_analysis_test.go:
逃逸分析如何运行
基本概念
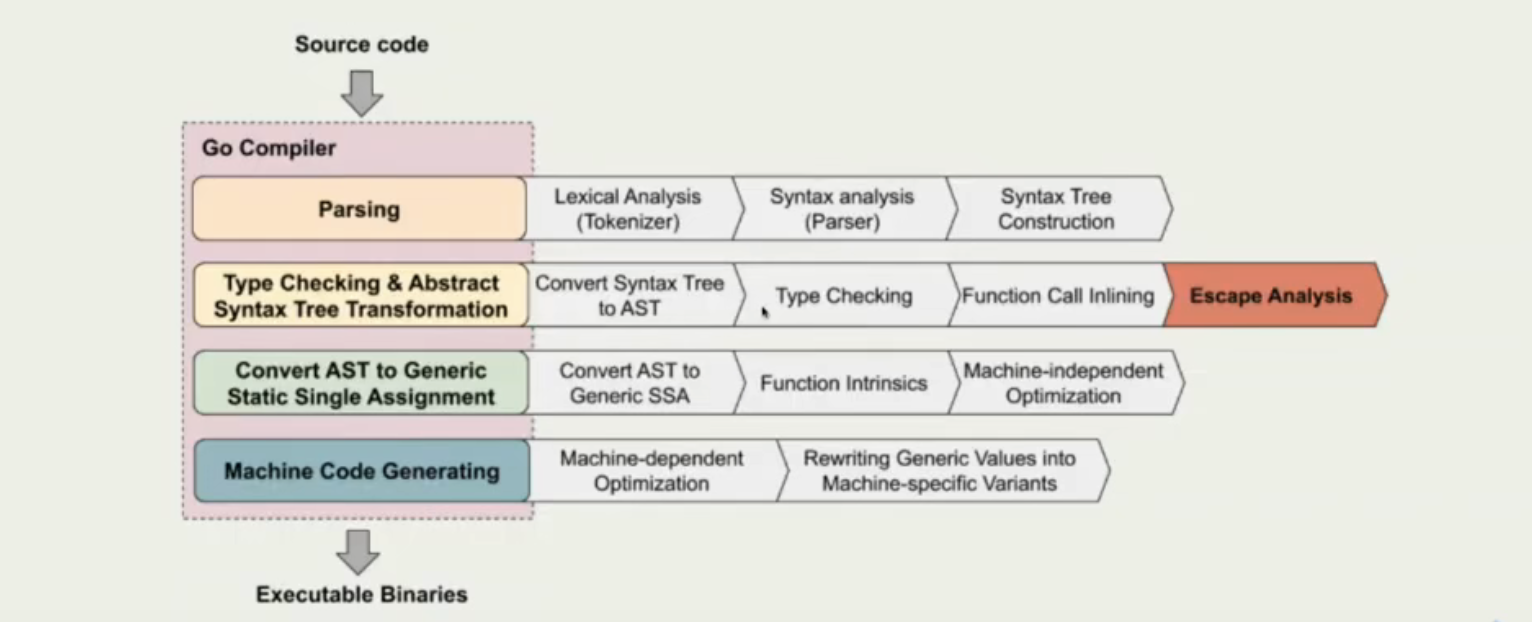
- 逃逸分析在源码库中的代码: escape.go,编译器所处的阶段如下图所示:
- 逃逸的概念
- 逃逸会分析声明变量之间的赋值关系
- 通常一个变量在以下情况下逃逸
- 被
&取地址 - 至少一个相关的变量已经发生逃逸
- 被
如何判断释放逃逸
判断是否逃逸,通过 data-flow-analysis 或者其他的基本规则。
数据流分析
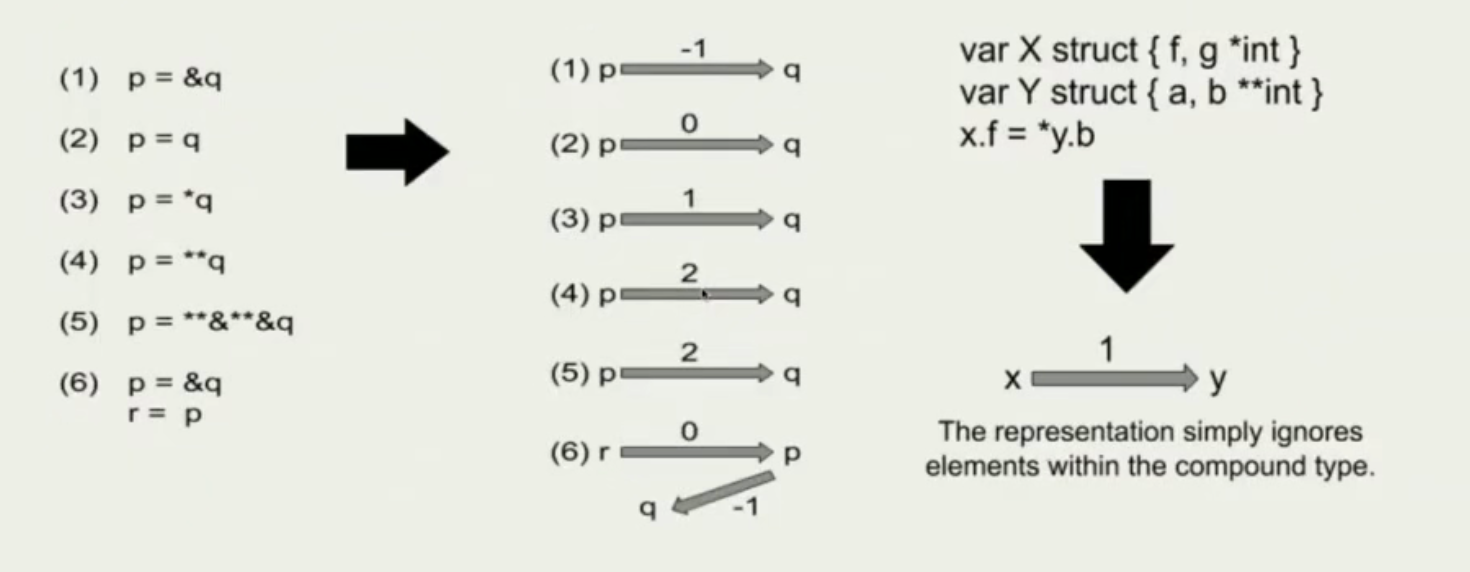
数据流分析是个有向无环图,它被用来基于AST分析变量之间的转换关系,有以下概念:
- 点
- 展示所有被声明的变量
- 边
- 代表变量之间的赋值逻辑
- 每条边都有权重,代表取地址/被引用的次数
具体例子如下图所示:
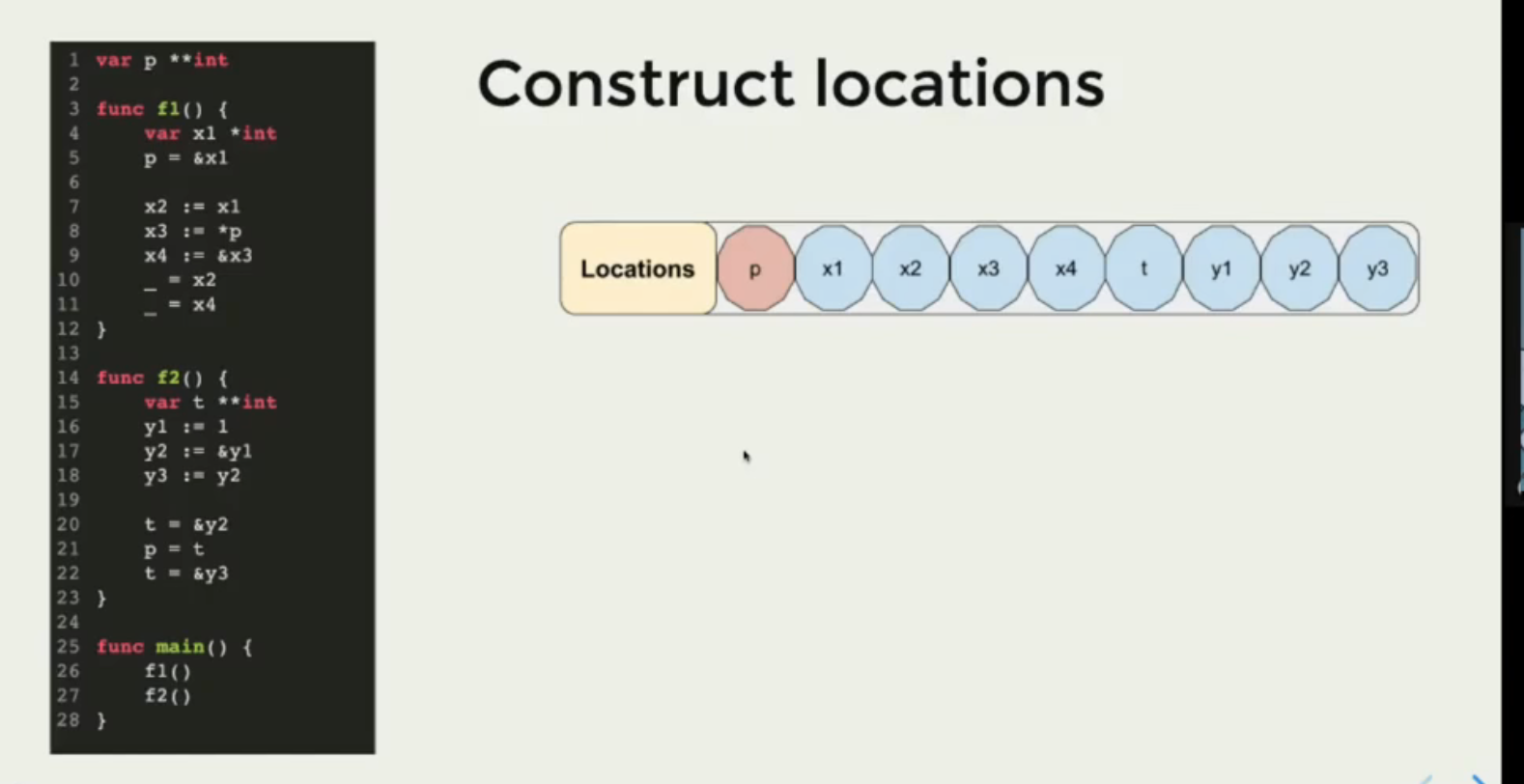
数据流分析的具体处理流程:
- 收集所有函数声明的变量,产出点
- 收集所有变量的赋值逻辑,产出边
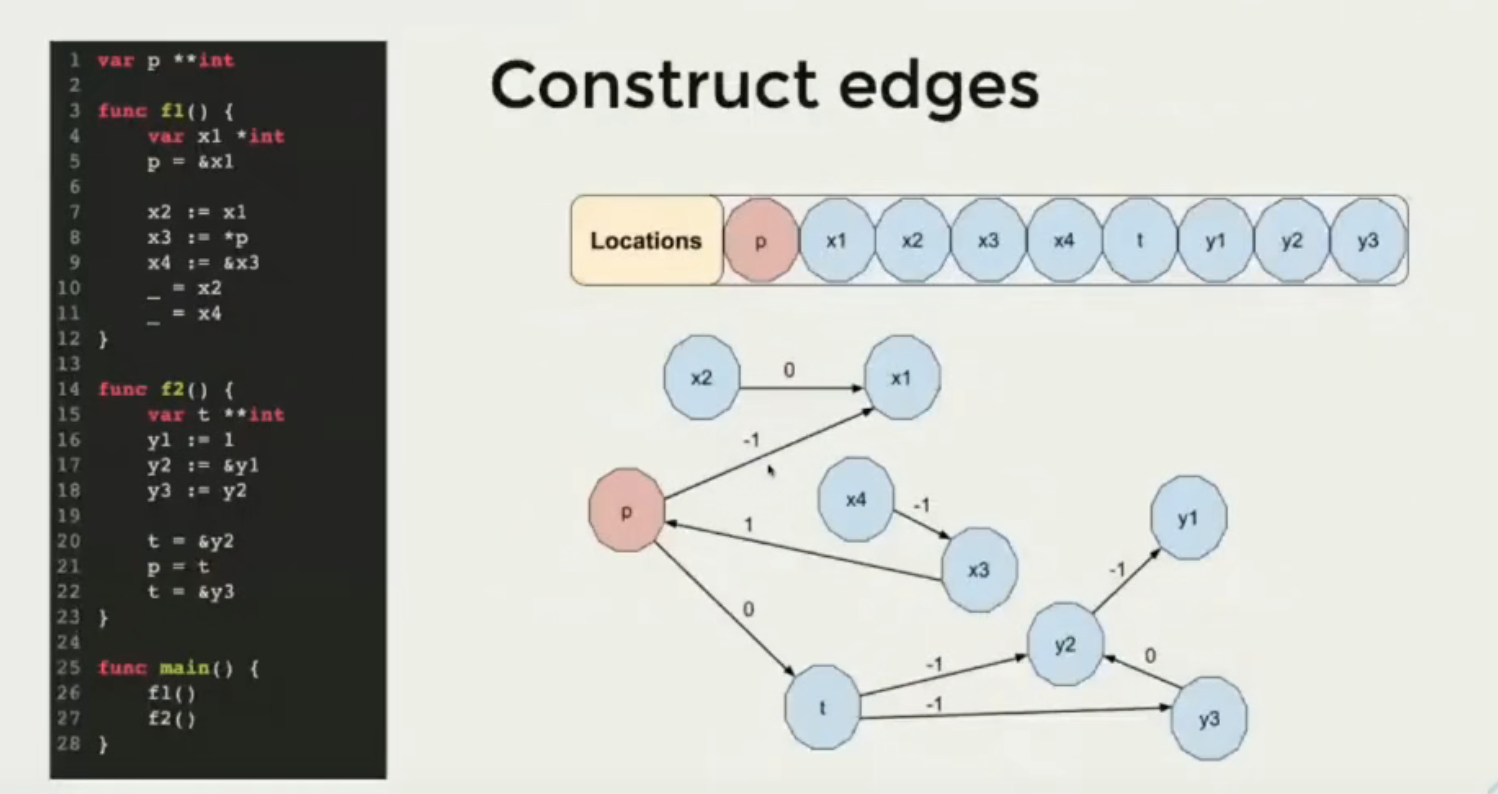
- 开始分析和遍历
- 从每个点开始分析
- 如果关联的源数据点已经逃逸,并且关联的边路径权重为-1,则当前变量也标识为逃逸
- 对于已经逃逸的变量,停止扩张分析
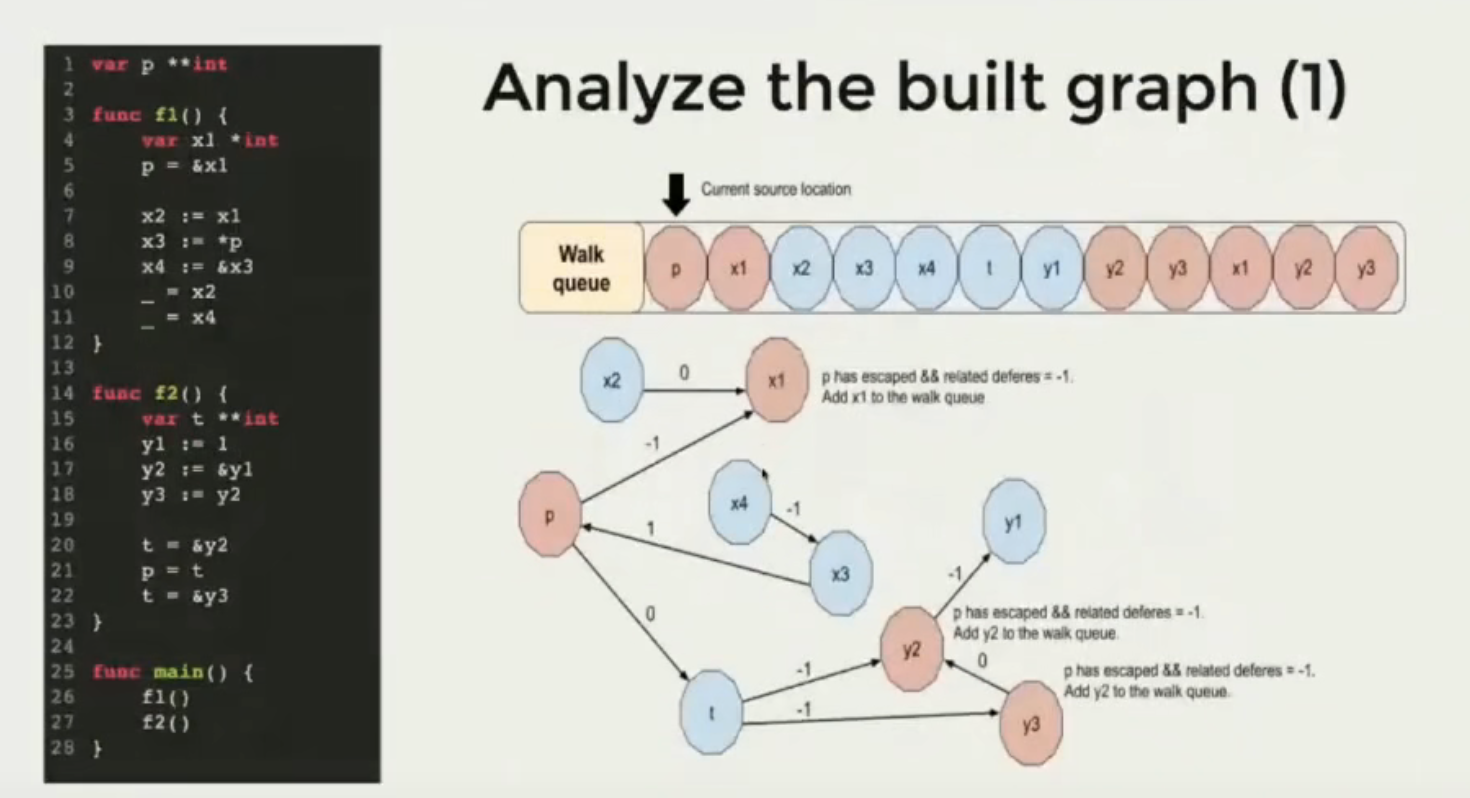
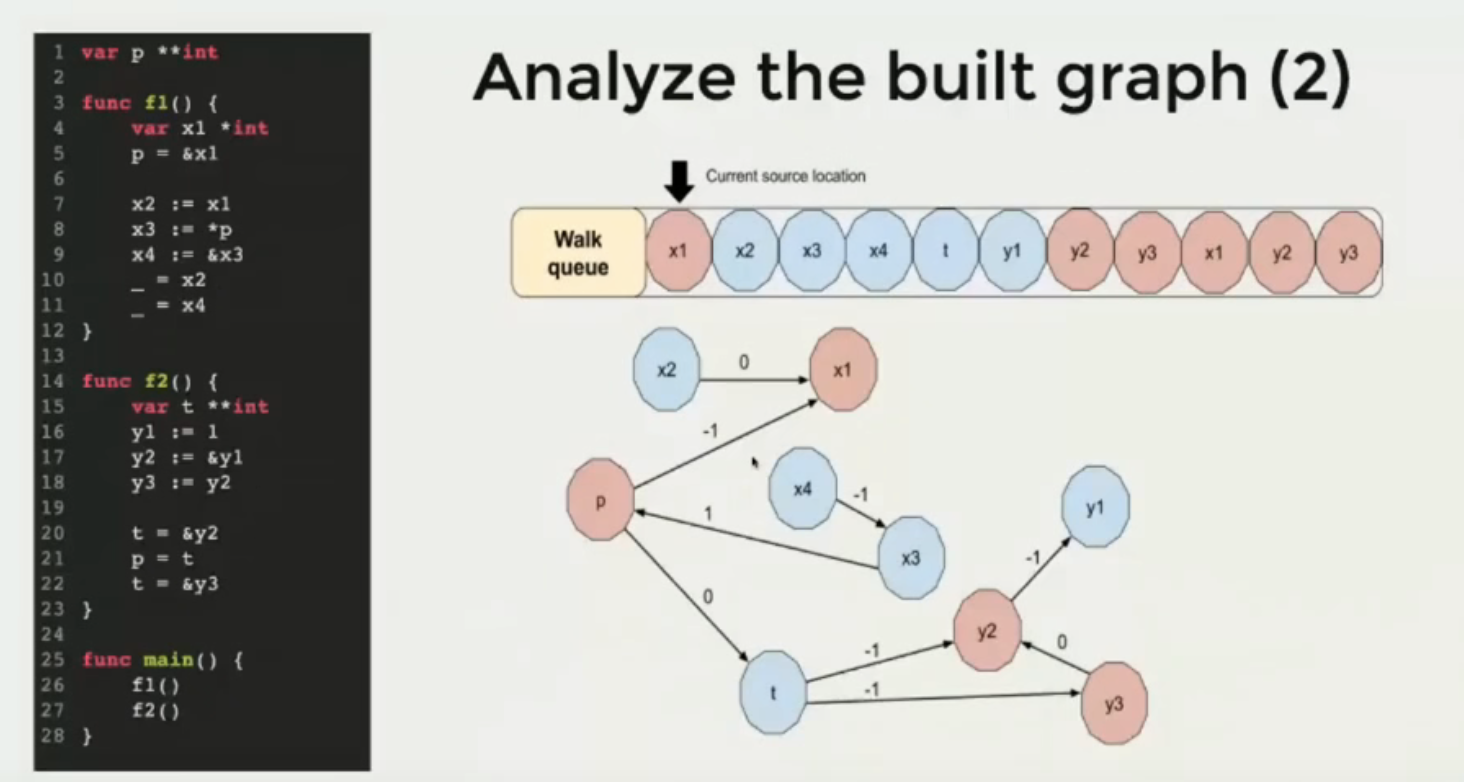
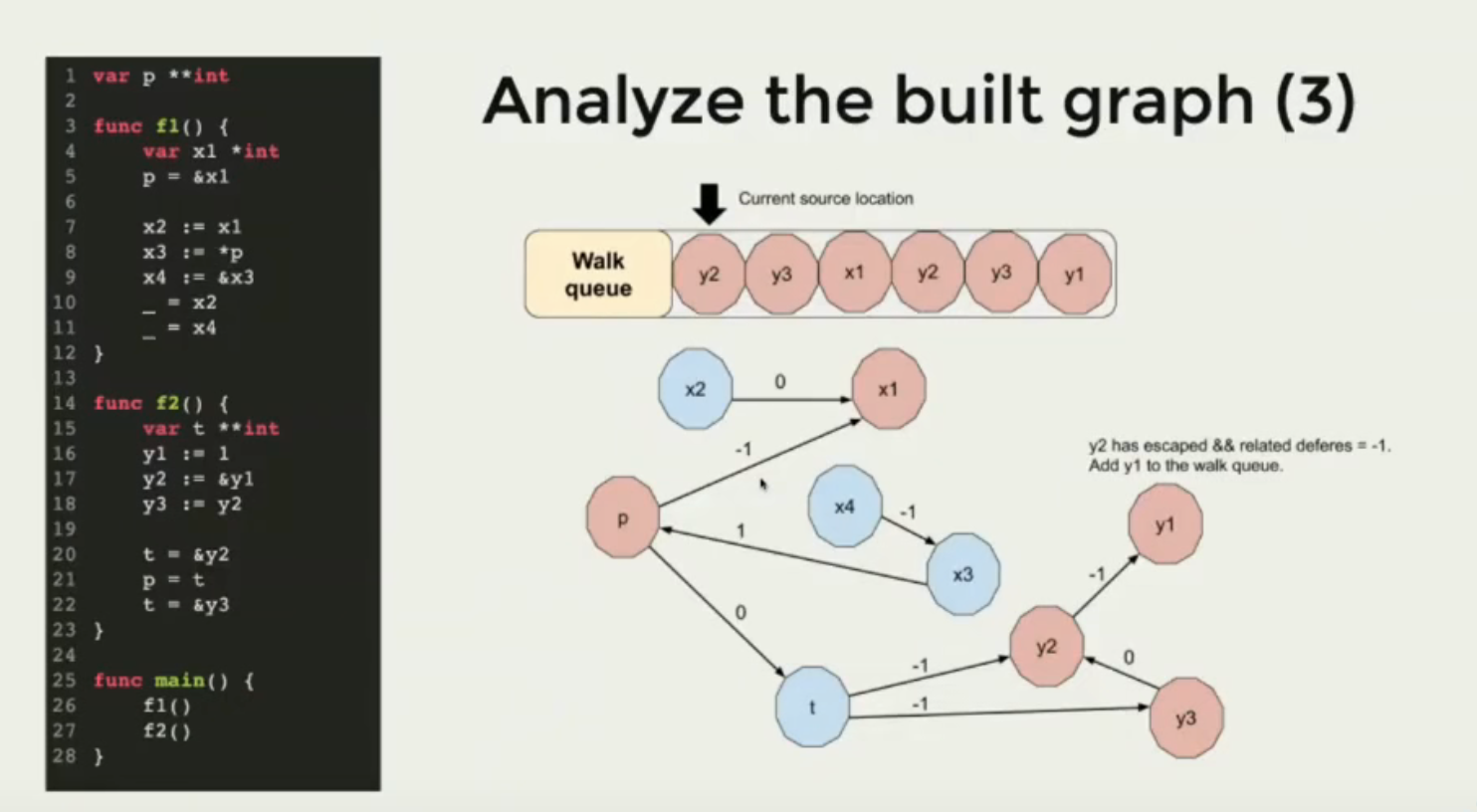
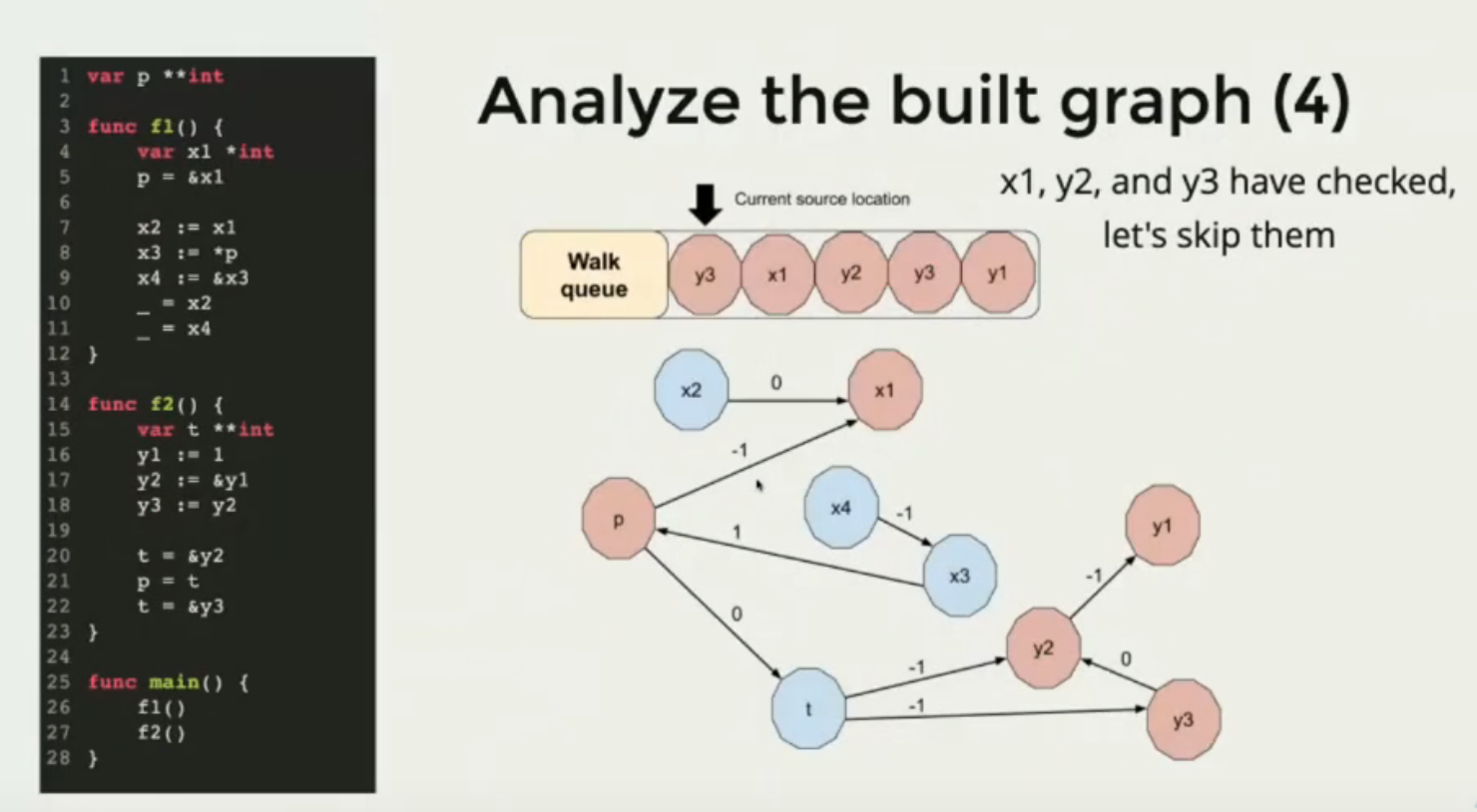
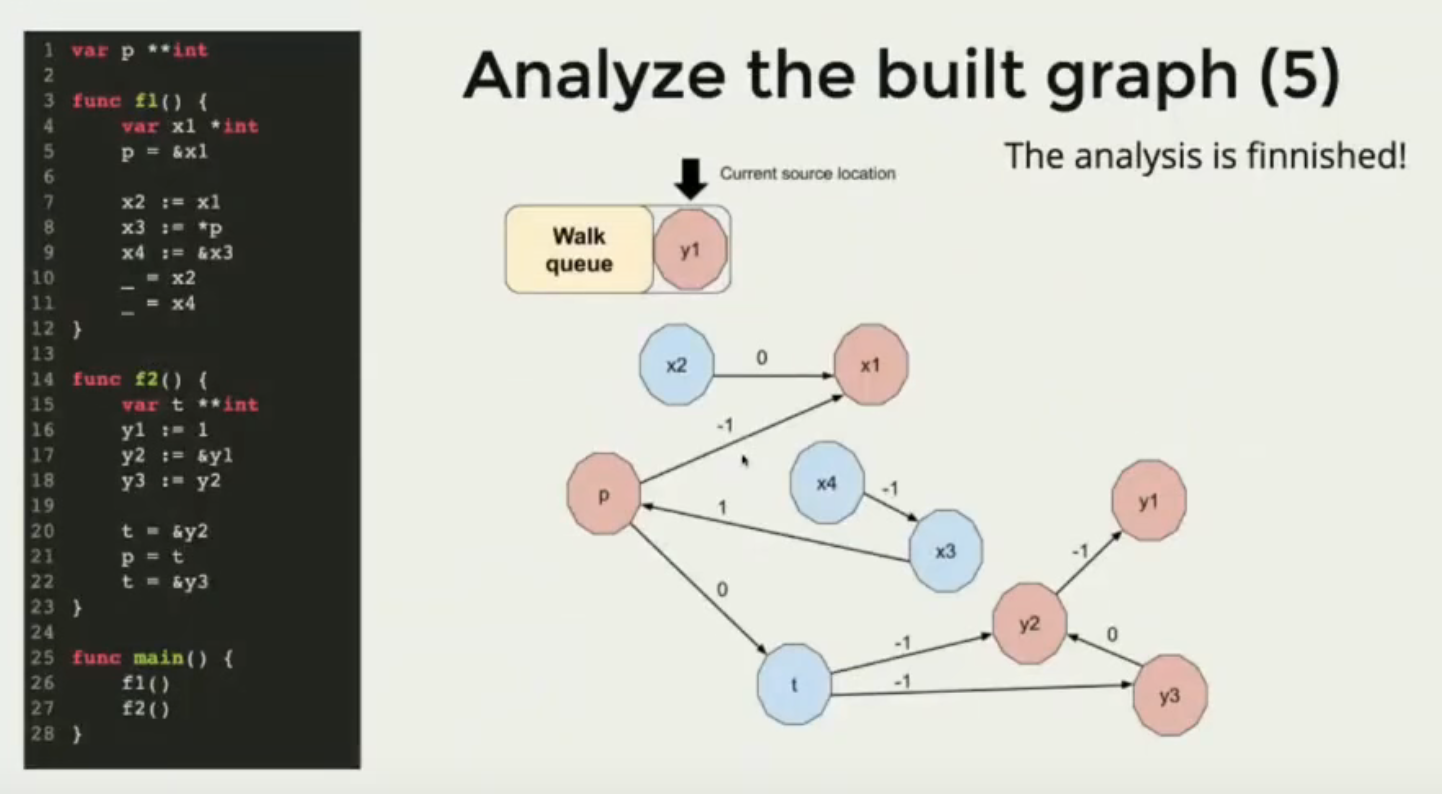
- 遍历所有变量,收集已逃逸变量的逃逸原因

其他基本规则
- 大对象
varor:=直接声明的变量,大小如果超过10MB,则分配到堆上- 隐式声明,大小超过64KB,则分配到堆上,比如make指定CAP值
- 切片,若切片通过
make关键字初始化,并且CAP值传的非常量,则分配到堆上,一定要常量! - 映射,如果一个变量被
map的key or value引用,则分配到堆上 - 函数入参,若函数入参泄露,则入参逃逸到堆上,Injecting changes to the passed parameters instead of return values back!
- 闭包外的变量,被闭包内变量取地址赋值使用,闭包内使用的参数一定要显示传进去!
上面规则的具体测试代码:
escape_analysis.go,通过-gcflag参数进行逃逸分析检查:
go build -gcflags '-l -m' escape_analysis.go
|
|
关于内联
上面逃逸分析命令中,-gcflags "-m -l"的 -l 就是全局禁止内联的含义,所以什么是内联呢,和前端CSS的内联样式一样吗。
什么是内联
在Go中,一个协程会有一个单独的栈,栈又会包含多个栈帧,栈帧是函数调用时在栈上为函数所分配的区域。但其实,函数调用是存在一些固定开销的,例如维护帧指针寄存器BP、栈溢出检测等。因此,对于一些代码行比较少的函数,编译器倾向于将它们在编译期展开从而消除函数调用,这种行为就是内联。
是否内联性能对比
函数非内联可以添加//go:noinline注释来实现,从下面的Benchmark可以看出来内联可以带来性能提升。
|
|
通过-gcflags="-m -m"参数,可以查看编译器的优化策略,搜索unhandled op关键字可以在
源码inl.go中发现目前只有下面几个关键字不支持内联:
case ir.OSELECT,
ir.OGO,
ir.ODEFER,
ir.ODCLTYPE, // can't print yet
ir.OTAILCALL:
v.reason = "unhandled op " + n.Op().String()
return true
同时内联还要求具体代码量不要太多。
什么情况下不应该内联
源码里有蛮多//go:noinline注释,目前还没理解什么情况下不应该内联。